Text to SQL in production
In January I wrote about our first efforts to integrate LLMs into our product. We used GPT-3 to translate natural language questions into SQL queries that answer them. At the time we decided that the technology wasn’t quite ready for our use case.
Since then we’ve lived through an LLM Cambrian explosion: the release of GPT-4 and friends, the growth of the open source ecosystem, and a bevy of literature about using these tools. We’ve continued iterating and now have a product that we're beta testing with our users.
This post will describe our solution to the Text-to-SQL problem and how we deployed this in our application. Many of the techniques described here are broadly applicable to using LLMs in production.
Prior Art
Spider is the most popular Text-to-SQL leaderboard. The current champions, Mohammadreza Pourreza and Davood Rafiei, kindly made the paper and code for their DIN-SQL algorithm publicly available. We modeled our program on their algorithm, which takes the following steps.
First, determine which tables and columns are needed to answer the question. The database schema is added to the prompt in plaintext, along with some few-shot prompts. Here's a simple example:
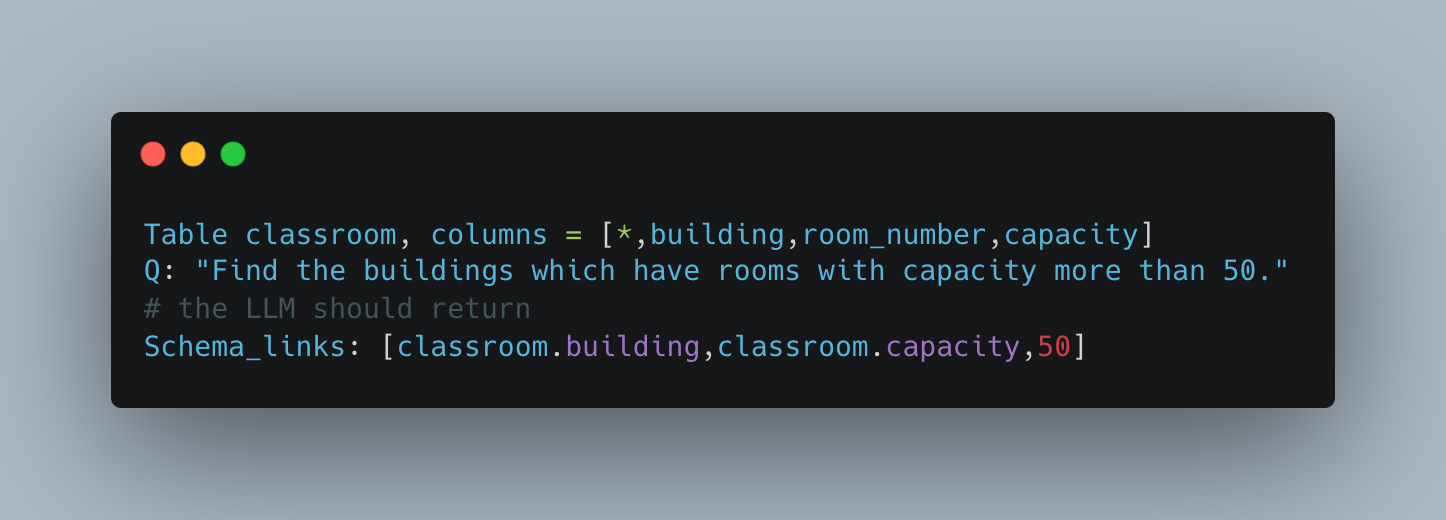
The authors call this step "schema linking".
Second, classify the question as requiring a SQL query that is one of EASY, NON-NESTED, or NESTED.
EASYquestions require no joins or subqueries, such as “How many users signed up in May” (answered with just the users tables)NON-NESTEDquestions requires a join but no subqueries, such as “How users with a payment method signed up in May” (users joined with payment method)NESTEDquestions require a subquery to answer, such as “How many teams had a user sign up in May”. (subquery of users that signed up in May, joined with teams, and then counting unique teams)
For both NON-NESTED and NESTED questions, the classification step also generates “Intermediate representations” - sub-questions that need to be answered before the larger question can be. Here's an example:
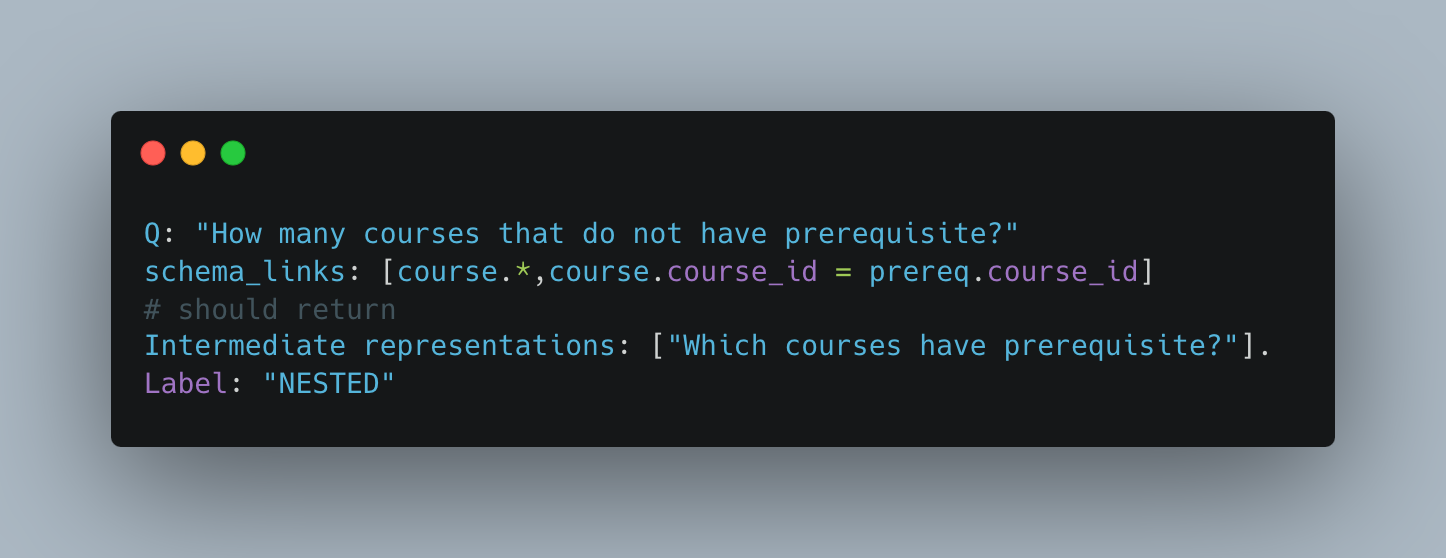
Third, depending on the result of the classification step, choose a prompting strategy to generate the SQL. An EASY query is simply given the question, schema, and schema links and GPT is entrusted to behave correctly. NON-NESTED and NESTED questions use Chain of Thought prompting whereby the LLM is guided on how to reason through the problem. The intermediate representations are used here to tell the LLM what steps the follow. Here's an example:

Finally, run a debugging step wherein GPT is given the database schema and prompted to fix any errors in the generated SQL, including some specifically enumerated areas to pay attention to.
Implementation
While the author’s code runs locally and single-threaded, our application needs to run in a web service as part of a distributed system. To run this as a service we chose Flask since its the lightest Python web framework, deployed in a Docker container in our Kubernetes cluster.
For calling GPT we use Langchain rather than the vanilla OpenAI Python library. Langchain is the leading library for working with LLMs and they offer a few things we need:
- Scaffolding and integrations for features like message history and vector stores (more on this later)
- A framework for agentic models (again, more on this later)
- The ability to plug-and-play new LLMs (if/when a viable GPT-4 competitor emerges)
- LLM call retries with backoff. Unfortunately, issues with OpenAI’s reliability make this a necessity.
We use the following Langchain call to get chat completions:
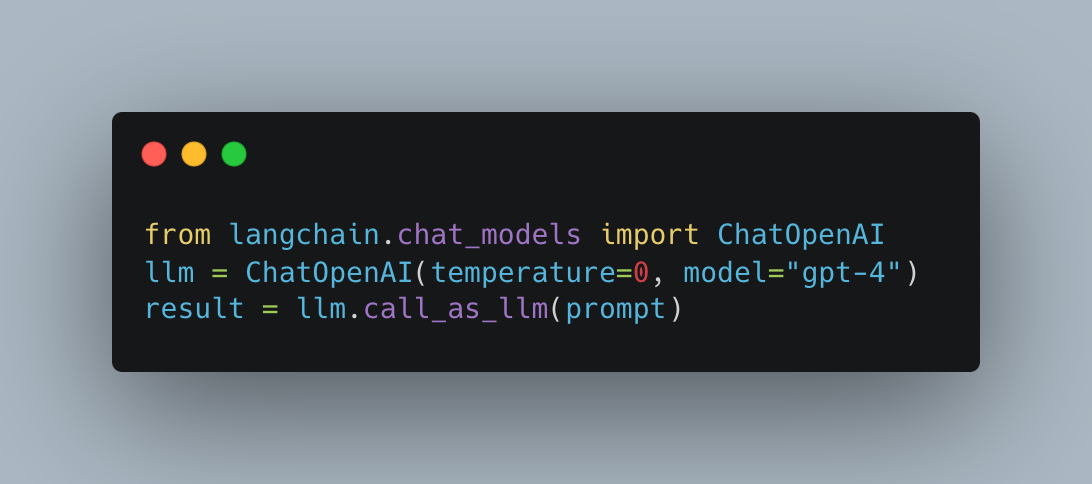
Besides this, we directly implemented the prompting scheme from the paper. This worked great when run against a local test database. Unfortunately, we immediately ran into token limits, that old bugaboo, when running questions against our warehouse.
The “Big” Problem
The biggest obstacle to implementing this - and I maybe any - Text-to-SQL algorithm in production is dealing with the size of the data schema. This metadata is essential for the program to function.
The Spider dataset is composed of SQLite databases with around 10 tables with 5-10 columns each. These schemas are small enough that an entire representation can be stuffed into a single prompt:
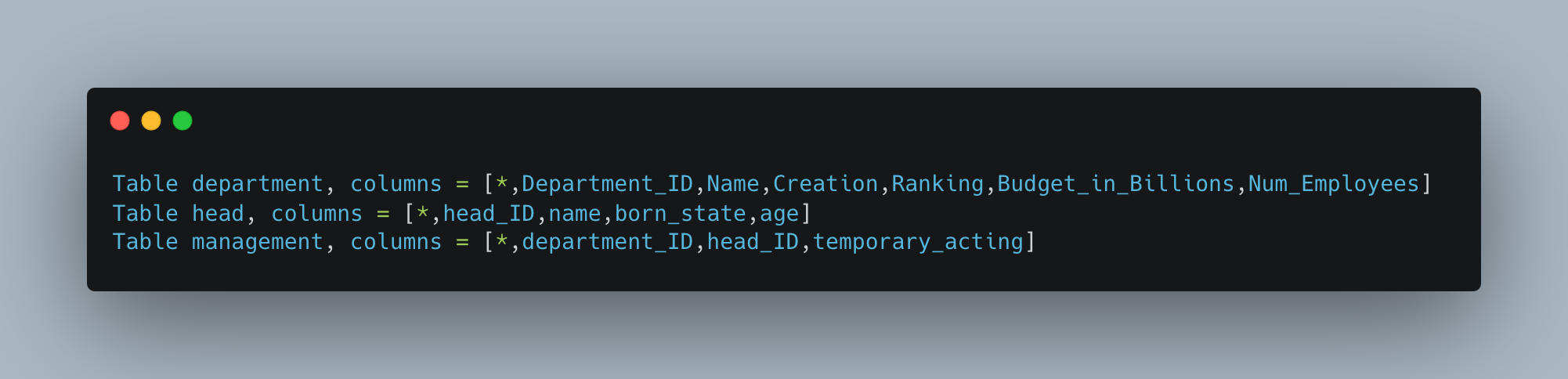
With data warehouses having hundreds of tables and dozens of columns (and more), this makes the algorithm unusable at scale. To resolve this we need a way to filter down the set of tables passed into the Schema Linking step to only those most likely to be needed by the query.
This brings us to the field of Information Retrieval, the science of finding the most relevant needle in the needle stack. In the world of LLMs this problem is usually solved with the use of a vector database, the new hotness on the scene. Vector stores are an excellent partner for LLMs because the API for both is natural language.
The mechanics of vector stores are beyond the scope of this post. The upshot is that a vector store allows you to insert text documents, then run a query for with some text and get back a list of documents ranked by their similarity to the input text. Crucially, similarity here does not mean syntactic similarity like the Levenshtein distance but rather semantic similarity.
This means that if we have a table called users with a field created_at in our vector store and then we query for “The people who signed up in May”, our users table would be highly ranked in the results.
There are a ton of options for vector databases right now. We used Chroma because of its speed and straightforward API. We also don’t have to worry about persistence right now since the vector store can be created just-in-time from the schema. Here’s the code to build the vector store:
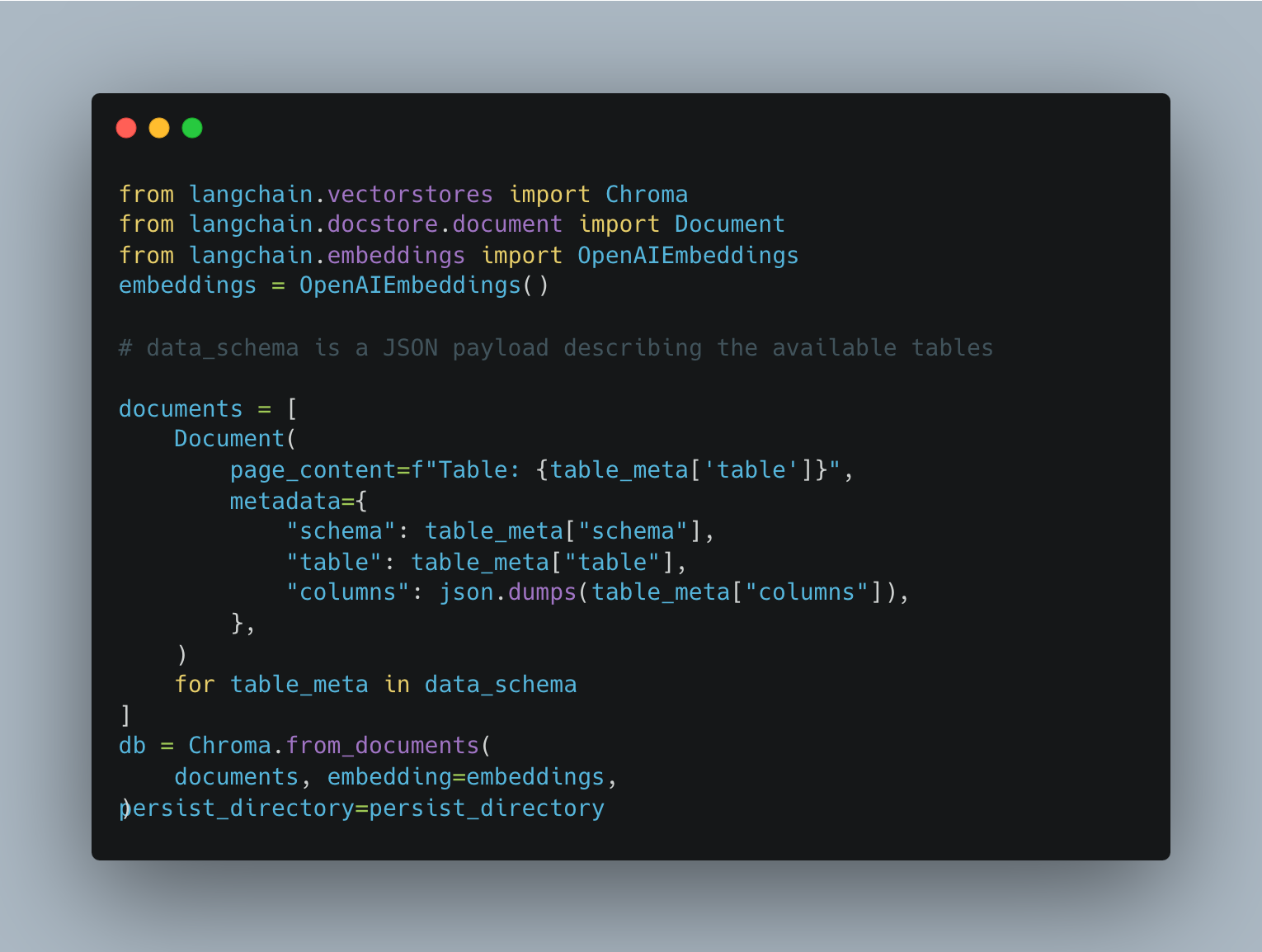
With that in place can implement our pre-processing step. We call this “entity extraction” after the information retrieval concept of named entity recognition.
Entity extraction
To use our vector store we need to extract the words that most likely refer to tables in the question. For example, if the user asks “What users have opened canvases recently?” we would want to extract the words “user” and “canvas” as referring to tables.
We construct the following prompt using the few shot approach:
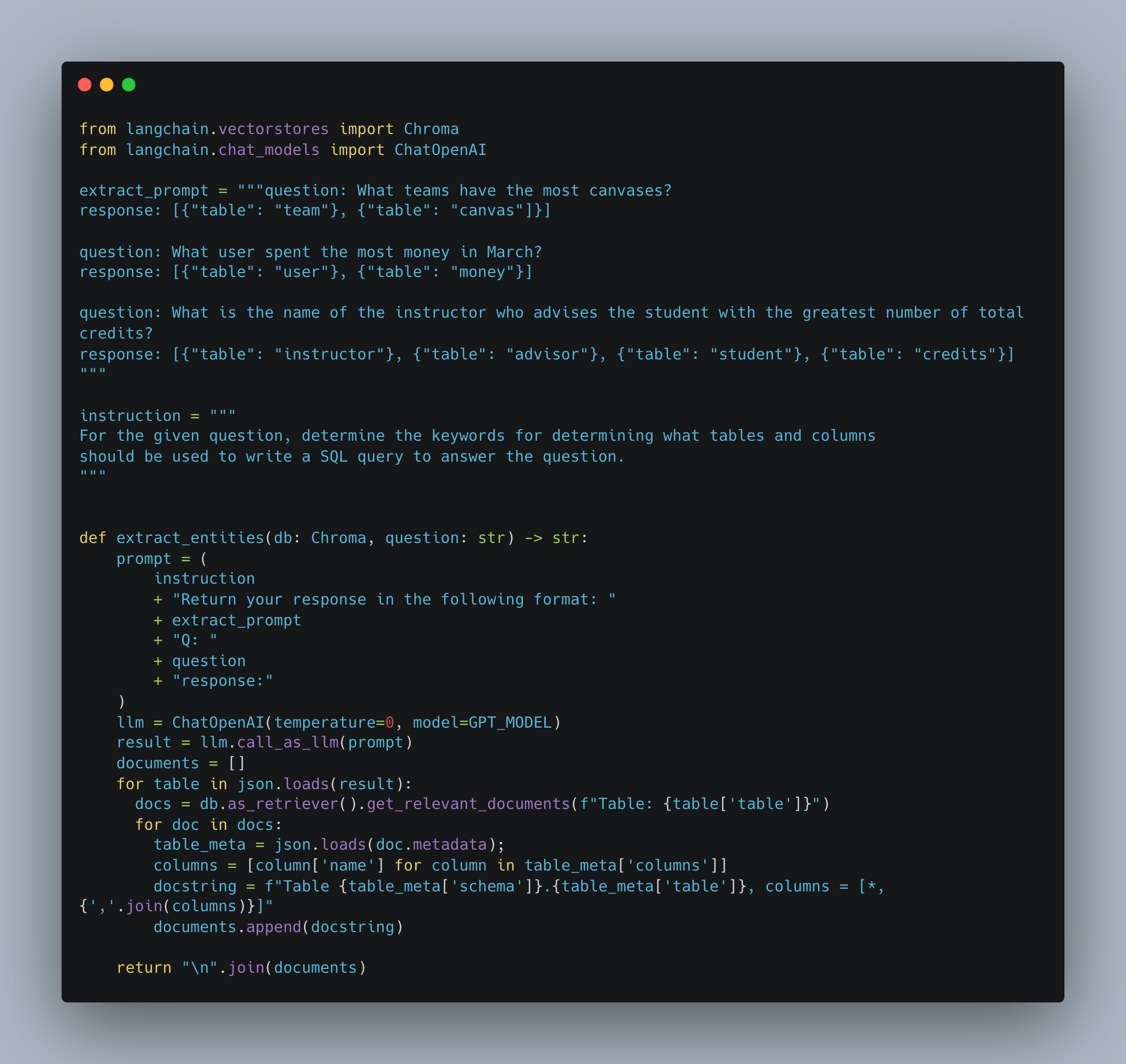
First we use GPT to extract the entities from the question. Next we iterate through these entities and, for each, query our document store. Finally, we return all of these documents concatenated together in the schema representation expected by the schema linking prompt.
get_relevant_documents by default returns the four best matching documents. For our purposes this is fine; we can provide multiple options to the next LLM step to decide which one to choose with the column and schema information included.
Improving on the state-of-the-art
As the authors suggest in their paper, we can improve upon the DIM-SQL algorithm by running queries against the database and feeding the result into GPT.
To do this we can use the Agent pattern, popularized by AutoGPT. To simplify a bit, agents run a loop until they meet some exit condition, calling making an LLM call in each iteration and using the output from that call to decide the inputs for the next call.
Langchain provides an out-of-the-box class for doing this, but we wrote our own since SQLAlchemy does not support all of the warehouses we need to and we wanted more granular control over how the LLM accessed our services.
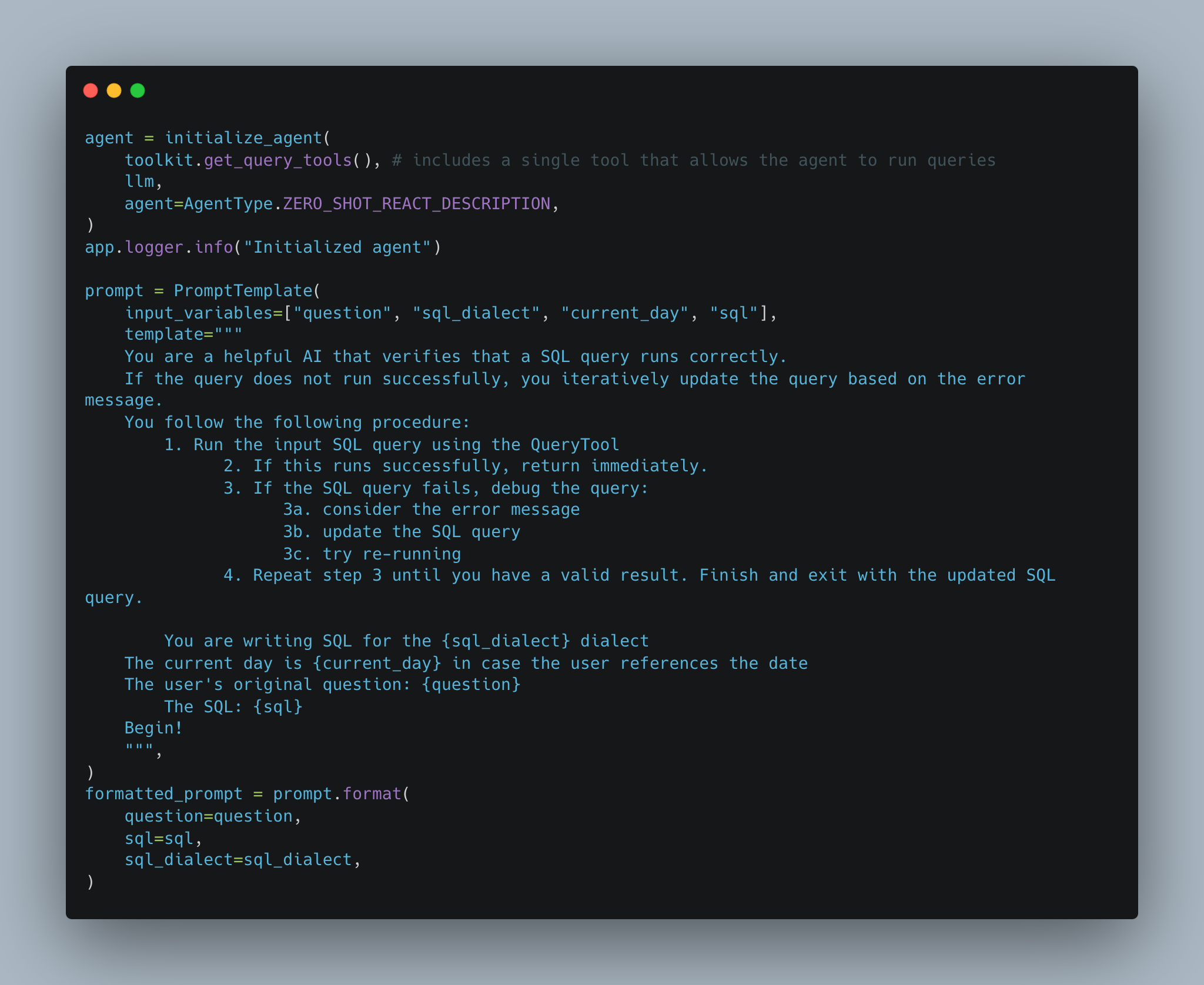
Using this final step the algorithm is able to catch invalid SQL as as well as check that the query result conforms to the format asked by the user.
For users that do not want their data sent to OpenAI we have the option to skip this step.
Putting it together
Finally let’s plug this into our frontend. We stream back the AI’s thought process to give the user immediate feedback, as well as help them understand the logic and catch any mistakes. All queries are run against our test data.

Pretty nice! The table aliases could be better named, but otherwise this is clean accurate code. Let’s try a more complicated question:
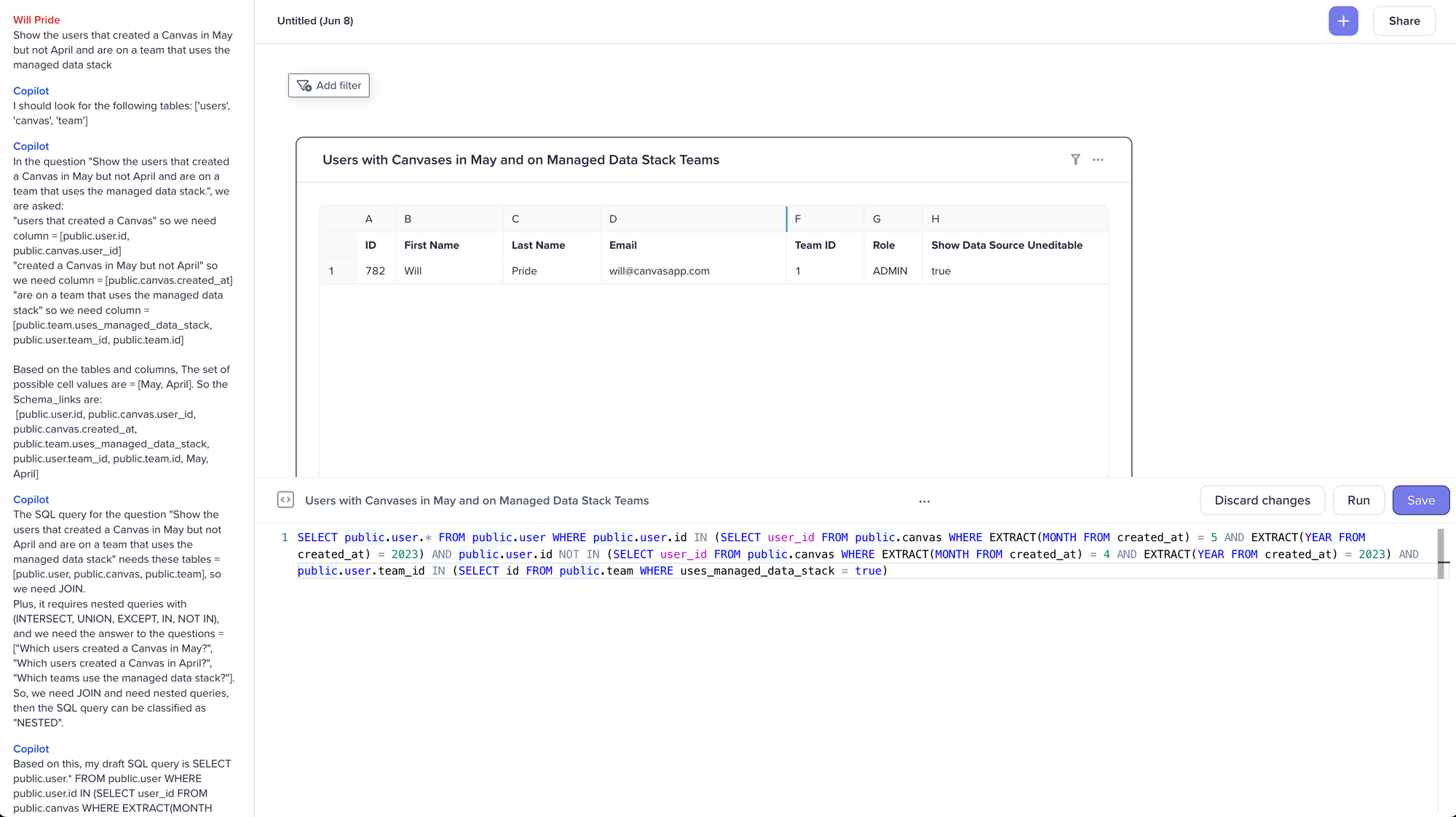
Pretty damn impressive. My main quibble is that with this many sub-queries I’d typically start breaking them into CTEs. But if our only concern is styling problems then I’m a happy guy.
Going live
We’re rolling this out to beta testers now, but a few major blockers remain before we can release our copilot generally.
First, the cost of running this code is non-trivial. GPT-4 is the only model capable of handling these tasks acceptably well. Some back-of-the-envelope math is that one 8k token completion costs around $0.40. We make between 6 to 10 calls to the API per question (depending on how many debugging steps are required) which means in the worst case each answer could cost $4.00! In practice I've never seen it come close to this, but we need to do a lot more testing and optimization before we can price this safely.
More importantly, we need to make sure this works. This is a new, non-deterministic coding paradigm that's effectively impossible to test with our existing methodologies. We have to watch our beta tester's usage closely. And beyond that, we need to design the UX in a way that keeps the human in the loop. This is a copilot, not an autopilot. If we’re delivering confidently incorrect answers to our users without audibility then we’re not doing our jobs correctly.
If you'd like to join the waitlist for beta testing, please click here. We're going to continue building in public, so sign up below if you want to follow our progress.
If you want to talk data and LLMs please drop me a line.
